 |
| AIのはてな |
第1回 人工知能(AI)とは
(1)人工知能(AI)とは
・AI、従来より映画、小説等、様々な物語りや、最近ではCMや電化製品や様々な分野で登場するキーワード、テーマであり聞きなれた単語でありますが、AIとは「Artificial
Intelligence」の略で、辞書的な定義では「学習・推論・判断といった人間の知能のもつ機能を備えた コンピューターシステム」と記されています。(大辞林
第三版より抜粋)
・「人口知能(Artificial Intelligence)」という言葉は1956年にアメリカで開催されたダートマス会議において、著名な人工知能研究者であるジョーン・マッカーシーが初めて使った言葉です。
しかし、「人工知能とは何か」については、専門家の間でも明確に定まっていないのが現状です。
それは、そもそも「知性」や「知能」自体の定義がないため、「人間と同じ知的な処理能力」の解釈が、研究者によって異なる事により、人工知能(AI)」という言葉は多義的で、人によってその捉え方は異なる為です。
(2)人工知能(AI)の歴史
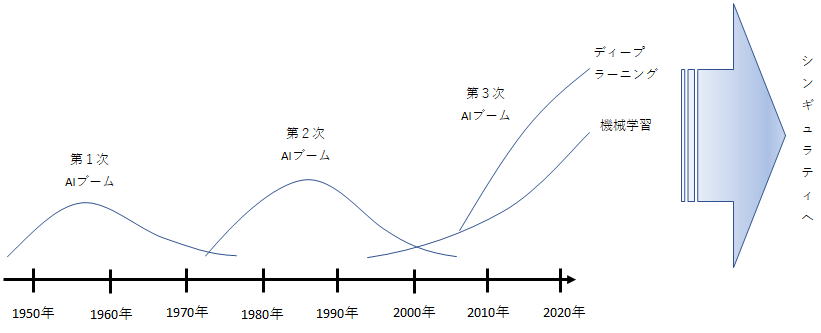
①第1次AIブーム「推論・探索」(1956年~1960年代)について
この時点のAIは、「推論・探索」によって問題を解決するといった方向で研究が進んでいました。
人間の思考過を記号で表現し実行する(推論)やその処理(探索)の発展形として、様々なアルゴリズムが考案されました。
それにより、コンピュータによる特定の難解な定理の証明や迷路の解き方、チェスやオセロといったトイプログラムによる処理が可能となりました。
また当時、冷戦中であった米国では、自然言語処理による機械翻訳の活用ができないかと、注目が集まりました。 相手国の情報を翻訳することで軍事利用できないかと考えたからです。
しかしながら、1969年にマービン・ミンスキーらが指摘したニューラルネットワークの限界や、様々な要因が絡み合っているような現実社会の課題を解くことはできないという「フレーム問題」が広く認識されたことで、第1次ブームは収束しました。
②第2次AIブーム「知識・エキスパートシステム」(1980年代)について
第2次ブームで注目されたのは「知識」で、この時代のブームを起こす引き金となったのが、多数のエキスパートシステムの実現です。
コンピュータが推論するために必要な様々な情報を、コンピュータが認識できる形で記述したものを「知識」として与えることで、人工知能(AI)が実用可能な水準に達し、多数の「エキスパートシステム」が生み出されました。
この「エキスパートシステム」の開発・導入がきっかけとなり、第2次AIブームが起こります。
「エキスパートシステム」とは、知識表現に重きを置き、専門家の知識から得たルールを用いて、特定の領域に関する質問に答える、人工知能が専門家のように振る舞うことができるプログラムです。
大量の「知識」によって、人工知能が病気を診断したり、判例を元に法律の解釈をするなど、現実の問題を解くことが可能となりました。
ただ当時はコンピュータが必要な情報を自ら収集して知識として蓄積することはできなかったため、必要となる全ての情報を、人がコンピュータに理解可能な内容で記述し、用意する必要がありました。
膨大な情報を、コンピュータが理解できるように記述して用意するためには、とてつもない作業になってしまい、人間側にも限界があるため、特定の領域の情報に限定しなければなりませんでした。
そのため、第1次AIブームで期待された機械翻訳も、人間の経験が細かく絡んでおり、その全ての情報を人間がコンピュータに伝えることは難しく実現できませんでした。
またコンピュータがいくら知識を増やしたとしても、あくまでも文字列での理解にしかならず、記号の意味をうまく結び付けられない「シンボルグラウンディング問題」やコンピュータには「常識」がないという問題も発生しました。
熱を下げるにはどうすればいいか?という質問に、「解熱剤を飲ませる」または「殺す」と返答するなど、そもそも命を守るという前提や倫理観を学ぶことはできなかったのです。
③第3次AIブーム「機械学習・ディープラーニング」(2010年~)について
近年のAIブームは、2つのテクノロジーの研究が大幅に進んだことで起こりました。それが「機械学習」「ディープラーニング」です。
機械学習に欠かせないものは、学習のために必要なデータです。近年、デジタル機器の急速な普及や通信技術の発達で大量のデータ・いわゆる「ビックデータ」が集まるようになりました。
「ビッグデータ」と呼ばれているような大量のデータを用いることで人工知能(AI)自身が知識を獲得する「機械学習」が実用化されました。
これまでとは比べ物にならない量のデータ収集・解析することで、人工知能は活躍の場を広げるようになります。
一方のディープラーニングとはこれまで人間が与えていたデータの特徴をAI自身が見つけ出す仕組みを指します。
これにより、AIは自ら新たな概念を理解したり、例外に対処できるようになりました。
従来の機械学習では人間が特徴量を定義し、予測や推論の精度を上げていましたが、「ディープラーニング(深層学習)」を活用することで、学習データから自動で特徴量を抽出し、精度を向上させることが可能になりました。
④シンギュラリティ(技術的特異点)について
レイ・カーツワイル博士は、「2029年にAIが人間並みの知能を備え、2045年にシンギュラリティ(技術的特異点)が来る」と提唱しています。
シンギュラリティ(技術的特異点)とは、AIがより優れたAIを作り出し、自ら人間より賢い知能を生み出す事が可能になる時点の事です。
又、シンギュラリティ(技術的特異点)が来るといわれている根拠となっている理論が、「収穫加速の法則」です。
収穫加速の法則とは、「技術進歩においてその性能が直線的ではなく、指数関数的に向上する」という法則。一度、技術的な進歩が起きると、その技術が次の進歩までの期間を短縮させ、ますますイノベーションが加速するという概念です。
シンギュラリティ(技術的特異点)が来ると人間以上の知性をもった「強いAI」や「汎用型AI」が登場し、人間では予測不可能な変化が起こると言われています。
![]()
| 推論 | 人間の思考過程を、記号で表現し実行しようとすること。 |
| 探索 | 目的となる条件(答え)を、解き方のパターンを場合分けして探し出すこと。 |
| トイプログラム | 明確なルールが定義されている単純な問題を扱うプログラム。 |
| フレーム問題 | 今しようとしていることに関係のある事柄だけを選び出す事が出来ない問題(限られた枠組み(フレーム)の中でしか有用でない問題) |
| エキスパートシステム | 人工知能に専門家のように「知識」をルールとして教え込み、問題解決させようとする技術のこと。 |
| シンボルグラウンディング問題 | 例えば、「馬」と「縞(シマ)」、それぞれの概念を知っている人はシマウマ=「馬」+「シマ」だと理解することができます。しかし、人工知能にはそれができない、というものです。 |
| 機械学習 | コンピューターが大量のデータを学習し、分類や予測などのタスクを遂行するアルゴリズムやモデルを自動的に構築する技術のこと。 |
| ディープラーニング | 人間が行うタスクをコンピュータに覚えさせ、複雑な問題を解決していく機械学習の実装手法の一つ。 |
| ビックデータ | 従来のデータベース管理システムなどでは記録や保管、解析が難しいような膨大なデータ群のこと。 |
| 特徴量 | 機械学習における特徴量とは、学習の入力に使う測定可能な特性のこと。たとえば、赤いリンゴと青いリンゴを識別する際には、「色」が特徴量となる。 人はものを識別する際に、無意識に適切な特徴量を利用するが、ディープラーニングを除く従来の機械学習では、識別に利用すべき特徴量を人間が入力していた。 これまで「人の顔の識別」などの複雑な問題において、人工知能に適切な特徴量を教えることが困難だった。 |
![]()
![]()
![]()
![]()
![]()